Speeding up CodeQA 2.5x
This blog post discusses the code on the optimization branch.
You can see PR diff here
Please read the below two posts if you want to know about how CodeQA works.
An attempt to build cursor's @codebase feature - RAG on codebases - part 1
An attempt to build cursor's @codebase feature - RAG on codebases - part 2
CodeQA is able to answer single hop, double hop questions well. It's also able to map english to obscure code snippets from the codebase. Features it lacks: It can't give you the whole flow of files or a specific part of codebase as cursor @codebase feature can but that's ok. Another one is it's slow, like really slow sometimes.
This made me feel dissatisfied. In worst case, it would take around 35-40 seconds to answer the question. I made some changes and now it runs under 15-20 seconds in the worst case. Roughly a 2.5x speedup. This blog post is about the changes I made to achieve the speedup.
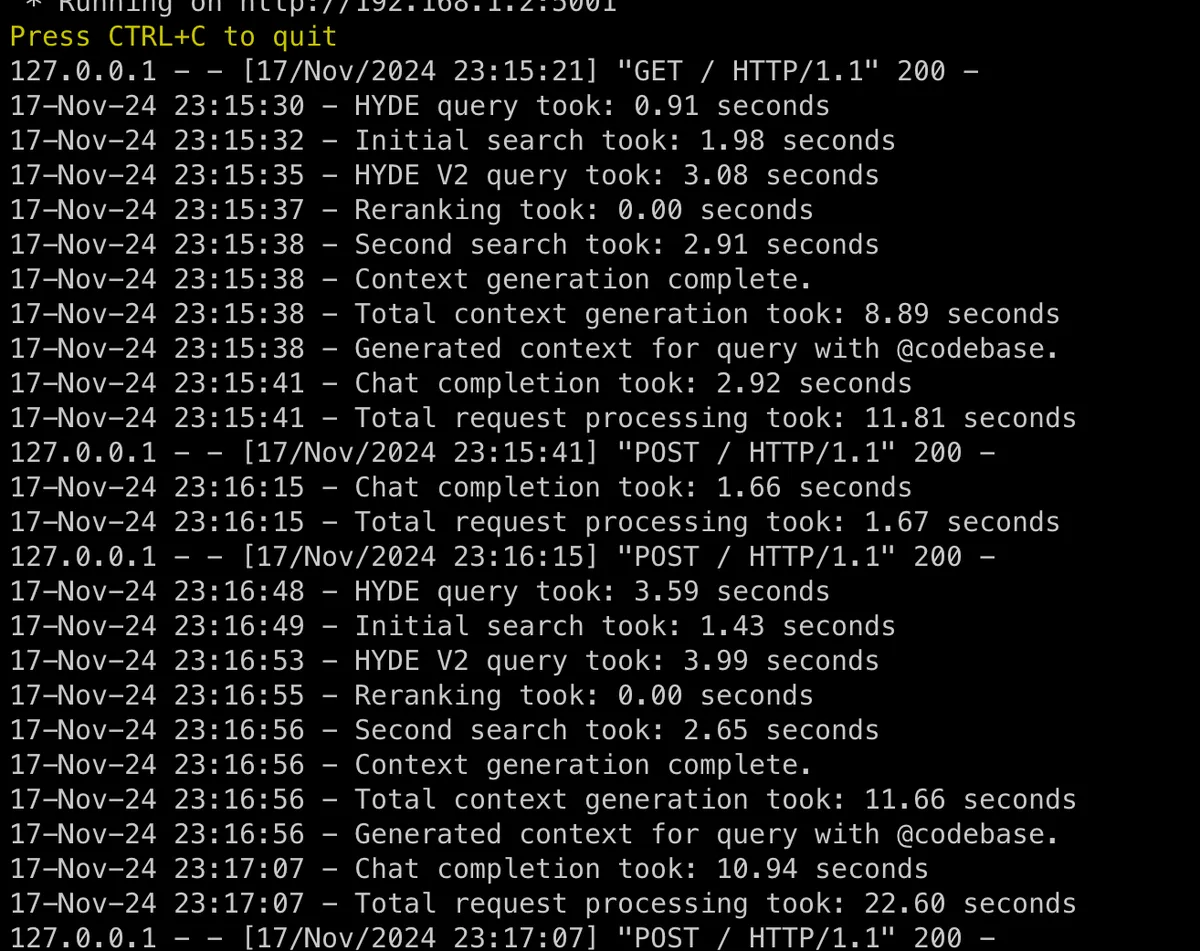 Figure 1: CodeQA Performance Before Optimization
Figure 1: CodeQA Performance Before Optimization
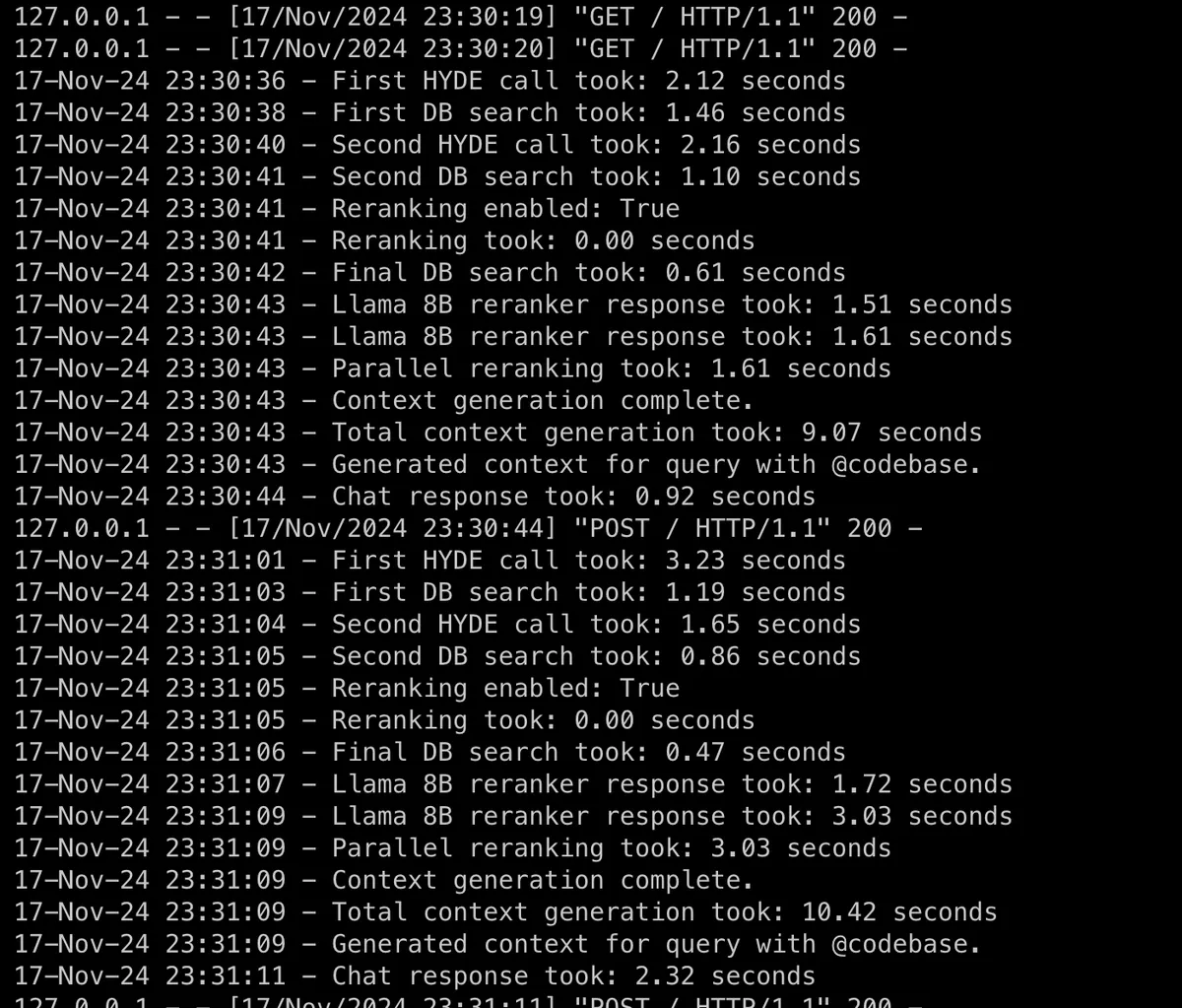 Figure 2: CodeQA Performance After Optimization
Figure 2: CodeQA Performance After Optimization
I asked two questions - first one about "what's the project about" and the second one "can you give me the full repo map strategy related code @codebase" on the locify project. (Note: this is not pictures from the worst case codebase, i am too lazy to try again and make sure to take screenshots)
Not much difference on first question but on second one, main branch codeQA took 22.6 seconds and optimized one took 10 seconds lesser (~12.7 total context gen + chat response)
Optimizations
There were mainly two bottlenecks:
- The HyDE calls taking 10-15 seconds
- The final chat response taking ~20 seconds at times
The HyDE call 1 problem rooted in the LLM generating an absurdly long output. The HyDE call 2 and the final chat response problem were rooted in the LLM processing a large context.
1. Token Optimization
first HyDE call where there's no context, tend to generate unnecessarily long outputs.
def openai_hyde(query):
chat_completion = openai_client.chat.completions.create(
model="gpt-4o-mini",
+ max_tokens=400,
messages=[
{
"role": "system",
"content": HYDE_SYSTEM_PROMPT
},
{
"role": "user",
"content": f"Predict code or documentation that would answer this query: {query}",
}
]
)
return chat_completion.choices[0].message.content
Manually tuned to 400 tokens based on output analysis. Even though Llama 3.1 70B is faster, I kept gpt-4o-mini for the first HyDE call since it generates higher quality initial predictions - crucial for the vector search step.
For HyDE call 2, I made max_tokens=768. I also made a change to optimise the original query instead of the
HyDE 1 query since we had context after the first HyDE call.
def openai_hyde_v2(query, temp_context, hyde_query):
- chat_completion = client.chat.completions.create(
+ chat_completion = openai_client.chat.completions.create(
model="gpt-4o-mini",
+ max_tokens=768,
messages=[
{
"role": "system",
- "content": HYDE_V2_SYSTEM_PROMPT.format(query=query, temp_context=temp_context)
+ "content": HYDE_V2_SYSTEM_PROMPT.format(temp_context=temp_context)
},
{
"role": "user",
- "content": f"Predict the answer to the query: {hyde_query}",
+ "content": f"Predict the answer to the query: {query}",
}
]
)
+ app.logger.info(f"Second HYDE response: {chat_completion.choices[0].message.content}")
return chat_completion.choices[0].message.content
2. Better Context Processing
Biggest performance hit came from chucking all the large context to the chat LLM - that too chatgpt-4o.
# Original approach - directly pushing large context to chat LLM
top_3_methods = method_docs[:3]
methods_combined = "\n\n".join(f"File: {doc['file_path']}\nCode:\n{doc['code']}"
for doc in top_3_methods)
top_3_classes = class_docs[:3]
classes_combined = "\n\n".join(f"File: {doc['file_path']}\nClass Info:\n{doc['source_code']} References: \n{doc['references']} \n END OF ROW {i}"
for i, doc in enumerate(top_3_classes))
# This large combined context was directly fed to the chat LLM
response = openai_chat(query, methods_combined + "\n" + classes_combined)
This was inefficient because the chat LLM was spending significant time processing this large context:
- Large amounts of context (methods, classes, references) were being pushed directly to the chat LLM
- Much of this context might not be relevant to the specific query. There could be duplicate context between methods and classes content too.
The Solution: Parallel Two-Stage Context Processing
I implemented a two-stage approach with concurrent processing. A crucial insight here was understanding that effective context filtering requires strong cross-attention between the query and the context - something that traditional reranking approaches might not provide as effectively.
Why not use reranking again at this stage? While reranking is effective for initial retrieval, it wouldn't be as powerful as an 8B language model for this specific task. Cross-encoders used in reranking are typically much smaller models, and they wouldn't capture the deep semantic relationships between query and context that we needed. The 8B model, with its full cross-attention mechanism, could better understand which parts of the context were truly relevant to the query.
This is one such instance where having the knowledge of how transformers and attention mechanisms work helped me with the insight.
- First, use a fast, lightweight model to filter the context:
def rerank_using_small_model(query, context):
chat_completion = client.chat.completions.create(
model='Meta-Llama-3.1-8B-Instruct', # 1000 tokens/second
messages=[
{
"role": "system",
"content": RERANK_PROMPT.format(context=context)
},
{
"role": "user",
"content": query,
}
]
)
return chat_completion.choices[0].message.content
- Then, use a faster model for the final chat response:
def openai_chat(query, context):
chat_completion = client.chat.completions.create(
model='Meta-Llama-3.1-70B-Instruct', # 400 tokens/second
messages=[
{
"role": "system",
"content": CHAT_SYSTEM_PROMPT.format(context=context)
},
{
"role": "user",
"content": query,
}
]
)
return chat_completion.choices[0].message.content
I also realized that methods_combined and classes_combined are independent contexts that can be processed separately. Here's how we concurrently processed the context filtering:
def process_methods():
top_3_methods = method_docs[:3]
methods_combined = "\n\n".join(
f"File: {doc['file_path']}\nCode:\n{doc['code']}"
for doc in top_3_methods
)
return rerank_using_small_model(query, methods_combined)
def process_classes():
top_3_classes = class_docs[:3]
classes_combined = "\n\n".join(
f"File: {doc['file_path']}\nClass Info:\n{doc['source_code']} References: \n{doc['references']}"
for doc in top_3_classes
)
return rerank_using_small_model(query, classes_combined)
# Concurrent execution of context filtering
with ThreadPoolExecutor(max_workers=2) as executor:
future_methods = executor.submit(process_methods)
future_classes = executor.submit(process_classes)
methods_context = future_methods.result()
classes_context = future_classes.result()
final_context = f"{methods_context}\n{classes_context}"
The key insights here were:
- Using SambaNova's Llama models strategically:
- Llama 3.1 8B (1000 tokens/second) for rapid context filtering
- Llama 3.1 70B (400 tokens/second) for generating the final response
- Processing methods and class contexts in parallel, which cut context filtering time by an additional 3-4 seconds
- Leveraging cross-attention in the 8B model for more intelligent context filtering than what traditional reranking could provide
Conclusion
The core lesson has been - to only supply as much relevant context as possible. Another overarching observation is if you find independent relevant context blocks, divide them and parallelize the calls (can't really parallelize in python but ok)
I feel better about the current state of CodeQA. It's fast, cheap and gives good quality answers. It could further be improved by using something like Groq's latest Llama 3.1 70b spec-decoded model that runs at 1600 tokens/second but I don't have developer api access yet.