learning gpu programming basics till flash attention probably as first milestone
log 31 march (i fell sick last 3-4 days. continuing from yesterday.)
next_power_of_two - use this model
stride - how many steps to skip for program. can do this instead of using contigous and flattening.
mask - is useful to avoid reeading 1023 extra tensors lets say we end up with one extra block due to ceiling division so we avoid reading and writing those.
vector addition
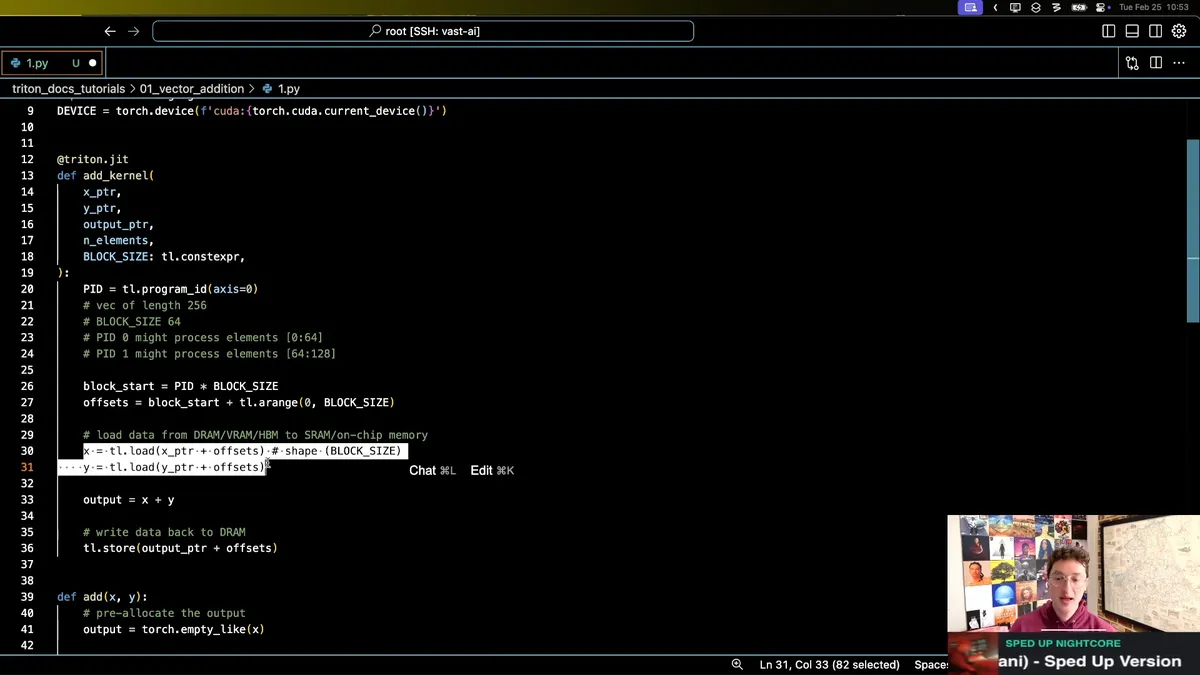
When you launch
n_elements = output.numel()
grid = lambda meta: (triton.cdiv(n_elements, meta['BLOCK_SIZE']))
How many different kernels are gonna get launched in parallel
images from the video - gpu compute basics

dram ~ vram hbm = high bandwidth memory
calculations happen on sram. point to note -> minimize transfers between sram and dram
DRAM is global SRAM is not - you have pools of SM core = smallest unit of compute -> don't even touch in triton warp = 32 threads -> can access in triton
i am currently on a small employment break so trying to pick up some things. basic gpu programming / low level memory stuff is something where i always feel bad when my friends talk about it. i am still intimidated by not knowing how flash attention works. so i would essentially ramp up my to that.
the real competition starts from 1st wee
GPU mode server folks are hodling practice mode on their discord. I started learning some triton + gpu basic programming / compute structure to compete for this.
i initially started writing my first kernel totally with help of claude + o1. the discord bot gives error traces so i was able to provide feedback back to the editor.
>be me
— sankalp (@dejavucoder) March 22, 2025
>doesn't know shit about gpu kernels
>gpu mode offering free gpu kernel benchmarking
>vibe codes to 19th position on 2nd problem on A100 category
>2 hours back and forth in docs
>stuck on 5th on a100 and 19th on h100 pic.twitter.com/7bbkTfkAYZ
after sometime, i started hitting up roadblocks (5th position on A100 leaderboard) so i started to read up the docs and a couple of blogs i know. i asked gpt4o/ o1 / claude sonnet 3.7 to explain the code from first principles. what could be wrong. what's the bottleneck etc.
openai models seem to be better at triton than sonnet...
i followed triton official documentation
went through a few lectures by cuda mode channel
Practitioner's Guide to Triton
https://github.com/gpu-mode/lectures/blob/main/lecture_014/A_Practitioners_Guide_to_Triton.ipynb
Planning to go through category
Going to skim through (very detailed)
https://alexzhang13.github.io/blog/2024/efficient-dl/
References